Я запустил сайт. Не шаблон на Tilda, не одностраничник на Notion - полноценный статический сайт на Astro, с блогом, лендингом продукта и двумя языками. И прежде чем написать первую статью в блог, я потратил непропорционально много времени на то, чтобы этот сайт правильно видели поисковики - и, что важнее, языковые модели.
Эта статья - о том, что я настраивал, зачем, и почему в 2026 году одного SEO уже недостаточно.
Зачем вообще свой сайт
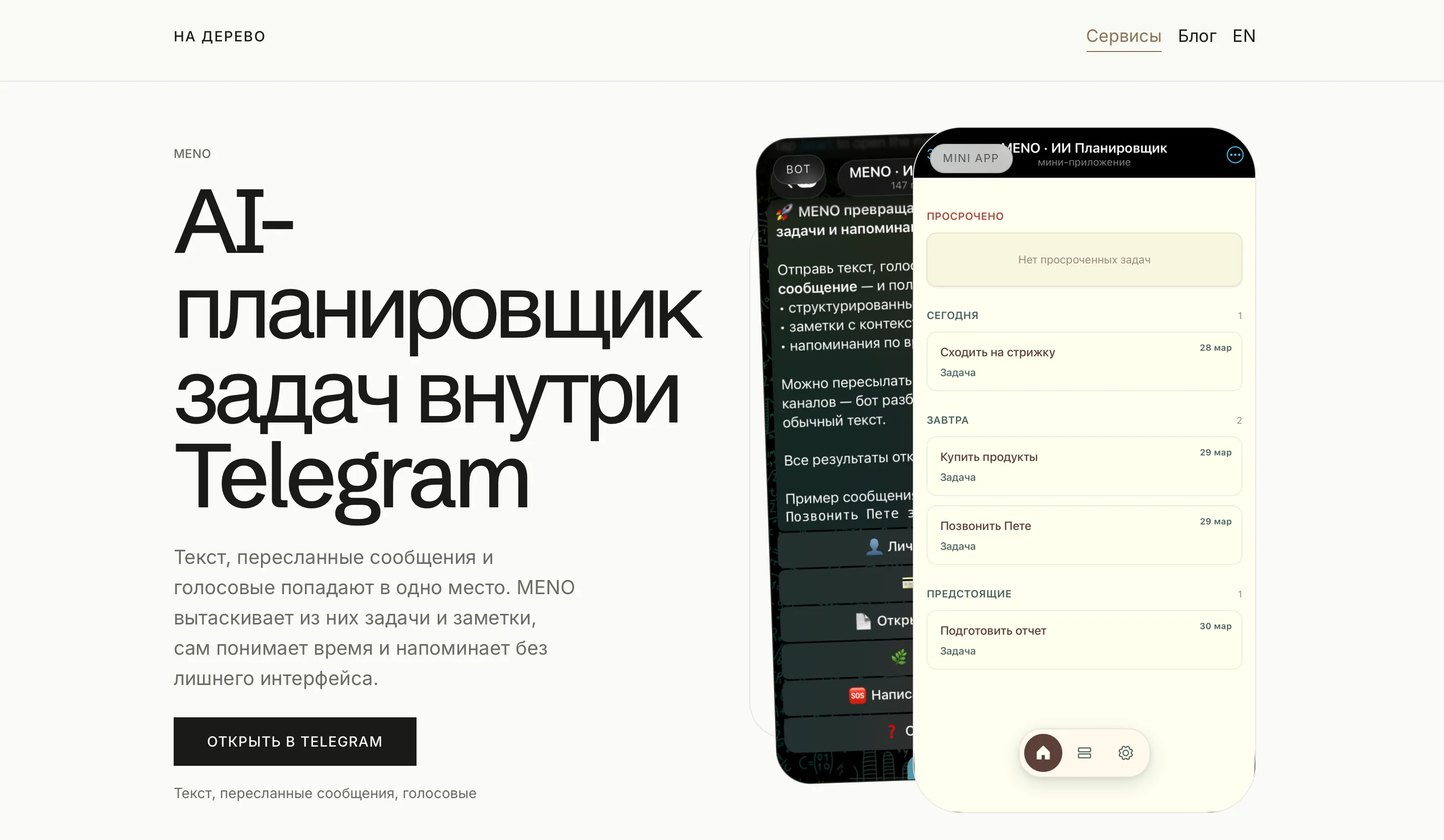
У меня есть проект “На Дерево” - я делаю цифровые инструменты и пишу о разработке. Главный продукт сейчас - Telegram-бот MENO для управления задачами. До этого всё жило на чужих площадках: статьи на Хабре, посты на dev.to, обновления в Telegram-канале.
Проблема: контент разбросан, ничего не связано, и если завтра какая-то площадка поменяет правила - я теряю всё.

Поэтому я сделал сайт, который решает три задачи:
- Лендинг MENO - чтобы было куда отправить человека, который хочет понять, что это за бот
- Блог - чтобы статьи жили у меня, а не только на чужих платформах
- Точка сборки - чтобы всё, что я делаю, было в одном месте
И ещё одна причина, менее очевидная.
POSSE: публикуй у себя, распространяй везде
Есть подход, который называется POSSE - Publish on Own Site, Syndicate Elsewhere. Идея простая: оригинал контента всегда живёт на твоём сайте, а на Хабр, dev.to, Reddit и куда угодно ты публикуешь копии.
Зачем:
- Права остаются за тобой. Ты автор, у тебя canonical, ты контролируешь текст.
- Не зависишь от площадки. Площадка может закрыться, забанить, поменять алгоритмы - у тебя всё лежит на своём домене.
- Можно подключать любые механизмы. RSS, рассылки, автопостинг - что угодно, без ограничений платформы.
Эта статья, кстати, тоже написана по POSSE - оригинал лежит в моём блоге, а то, что вы читаете сейчас, - синдицированная версия.
Техническая база: Astro и два языка
Сайт собран на Astro - это фреймворк для статических сайтов. Никакого клиентского JS для контента, всё рендерится в чистый HTML при сборке. Для поисковиков и AI-краулеров это идеально: они видят готовую страницу, а не пустой <div id="app">, который нужно ещё исполнить.
Сайт двуязычный:
/ru/- русская версия/en/- английская версия
Статьи блога хранятся в Markdown через Astro Content Collections - по файлу на каждый язык. Это позволяет вести один блог на двух языках, при этом каждая статья знает о своей альтернативной языковой версии.
Корень сайта (/) - это не контентная страница. Это redirect-entry: скрипт определяет язык браузера или сохранённый выбор пользователя и перенаправляет на /ru/ или /en/. Для UX это удобно. Для SEO - компромисс, о котором ниже.
SEO: что настроено и почему
SEO в 2026 году - это не “вписать ключевые слова в текст”. Это набор технических сигналов, которые помогают поисковику понять, что на странице, на каком языке, и какую версию показывать пользователю.
Вот что я настроил.
Базовые мета-теги
Каждая страница имеет свои собственные:
<title>- заголовок, который видно в поисковой выдаче<meta name="description">- описание под заголовком в выдаче
Звучит очевидно, но количество сайтов, где на всех страницах одинаковый title, - удивительно. У меня title и description уникальны для каждой страницы: главная, лендинг MENO, каждая статья блога.
Canonical
<link rel="canonical" href="https://naderevo.com/ru/blog/my-article/" />Canonical говорит поисковику: “вот оригинал этой страницы”. Если контент доступен по нескольким URL - например, с параметрами и без - canonical указывает, какой URL индексировать. Без него поисковик может посчитать дубли за разные страницы и размазать рейтинг.
Hreflang
<link rel="alternate" hreflang="ru" href="https://naderevo.com/ru/blog/my-article/" />
<link rel="alternate" hreflang="en" href="https://naderevo.com/en/blog/my-article/" />Hreflang - это способ сказать поисковику: “у этой страницы есть версия на другом языке, вот она”. Google использует hreflang, чтобы показывать пользователю правильную языковую версию в выдаче.
У меня hreflang настроен для всех страниц, включая статьи блога. Альтернативные ссылки строятся по routeSlug - специальному полю в frontmatter статьи, которое явно задаёт URL. Это надёжнее, чем полагаться на автоматические slug’и.
Open Graph и Twitter Cards
<meta property="og:title" content="..." />
<meta property="og:description" content="..." />
<meta property="og:image" content="..." />
<meta name="twitter:card" content="summary_large_image" />Это то, что видно, когда кто-то делится ссылкой в соцсетях или мессенджерах - заголовок, описание, картинка. Без OG-тегов ссылка выглядит как голый URL. С ними - как карточка.
Пока я использую универсальные OG-картинки: одну для сайта, одну для блога, одну для MENO. Не идеально для CTR, но на текущей стадии - достаточно.
Robots.txt и Sitemap
User-agent: *
Allow: /
Sitemap: https://naderevo.com/sitemap-index.xmlrobots.txt открыт для всех - и для поисковых ботов, и для AI-краулеров. Никаких блокировок.
Sitemap генерируется автоматически при сборке и содержит все индексируемые страницы. Из него убраны мусорные URL и корень / (потому что это redirect, а не контент).
Structured Data (JSON-LD)
Это разметка, которая помогает поисковику не просто прочитать страницу, а понять, что на ней. Не “текст про бота”, а “это программный продукт, вот его название, вот автор, вот рейтинг”.
На сайте три типа structured data:
WebSiteна главной - описание сайта как сущностиSoftwareApplicationна лендинге MENO - описание продуктаBlogPostingна статьях - описание каждой статьи с автором, датой, заголовком
Пример того, как это выглядит для статьи:
{
"@type": "BlogPosting",
"headline": "Как я перестал терять задачи в Telegram",
"author": {
"@type": "Person",
"name": "Nikita"
},
"datePublished": "2026-07-10",
"description": "..."
}Поисковик видит это и может использовать для rich snippets - расширенных карточек в выдаче.

GEO: что это и зачем
А теперь про то, что многие пока не учитывают.
GEO - Generative Engine Optimization - это оптимизация сайта не для поисковых роботов, а для языковых моделей. ChatGPT, Perplexity, Gemini, Claude - все они умеют ходить по сайтам, читать контент и цитировать его в ответах. Вопрос: будет ли среди процитированного ваш сайт?
Если SEO - это “как попасть в выдачу Google”, то GEO - это “как попасть в ответ ChatGPT”.
Звучит как что-то из далёкого будущего, но это уже работает. Люди всё чаще ищут не в Google, а спрашивают у AI. И AI берёт информацию откуда-то. Если ваш контент чистый, структурированный и доступный для краулинга - шансы попасть в ответ выше.
Что важно для GEO
Контент в чистом HTML, а не в клиентском JS. AI-краулеры не всегда исполняют JavaScript. Если ваш контент рендерится на клиенте - модель может увидеть пустую страницу. Astro рендерит всё в HTML при сборке - краулер видит готовый текст.
Не блокировать AI-краулеров. Некоторые сайты в robots.txt блокируют ботов ChatGPT, Anthropic и других. Я сознательно оставил всё открытым. Если модель хочет прочитать мой контент и сослаться на него - пожалуйста.
Structured data. JSON-LD помогает не только Google, но и языковым моделям. Когда на странице есть разметка BlogPosting с автором, датой и описанием - модели проще понять контекст и решить, стоит ли цитировать.
Авторский слой. Это менее очевидный, но важный момент. Контент без автора выглядит безличным. Модель не может атрибутировать его, а значит - с меньшей вероятностью процитирует. Я добавил видимый авторский блок на каждую статью и перевёл author в schema на тип Person с именем.
Что GEO не закрывает (пока)
Корень сайта остаётся redirect-entry - для языковой модели это слабая страница. Если кто-то спросит AI “что такое naderevo.com”, модель может не получить ответ с корня, потому что там нет контента - только скрипт перенаправления.
Сравнительные статьи в блоге можно усилить ссылками на первоисточники - это повышает доверие модели к контенту.
Главная страница брендовая, но не answer-first - она не отвечает на вопрос прямо в первом абзаце. Для GEO лучше, когда страница начинается с прямого ответа, а потом раскрывает подробности.
Всё это - не критично, но остаётся в списке на доработку.
Google Search Console и Яндекс.Вебмастер
В день написания этой статьи я зарегистрировал сайт в Google Search Console и Яндекс.Вебмастере. Статистики пока нет - обоим нужно время на обработку.
Зачем это делать, даже если у вас новый сайт с нулевым трафиком:
- Вы сообщаете поисковику о своём существовании. Без регистрации Google может найти ваш сайт сам - а может и не найти. Search Console - это гарантия.
- Можно отправить sitemap вручную. Поисковик начнёт обходить страницы быстрее.
- Видно ошибки индексации. Если что-то сломано - hreflang, canonical, redirect - Console покажет. Лучше узнать сейчас, чем через три месяца.
- Данные о запросах. Когда трафик появится, вы будете видеть, по каким запросам люди находят сайт, какие страницы показываются и с каким CTR.
Для Яндекса всё аналогично, только через Вебмастер. Если вы ориентируетесь на русскоязычную аудиторию - это обязательно.
Я зарегистрировался в обоих. Через пару недель посмотрю, что они нашли, и расскажу.
Lighthouse: проверяем, что всё не зря
Ещё один инструмент, про который стоит знать, - Lighthouse. Это встроенный аудит в Chrome DevTools, который оценивает страницу по четырём параметрам:
- Performance - как быстро страница загружается и становится интерактивной
- Accessibility - насколько сайт доступен: контраст, alt-тексты, навигация с клавиатуры
- Best Practices - соблюдение веб-стандартов: HTTPS, корректные заголовки, отсутствие устаревших API
- SEO - базовая техническая SEO-гигиена: meta-теги, canonical, читаемость для краулеров
Каждый параметр оценивается от 0 до 100. Зелёная зона - от 90. Это не гарантия успеха в выдаче. Прогнал свой сайт. Результаты:
Главная страница:
| Performance | Accessibility | Best Practices | SEO |
|---|---|---|---|
| 99 | 100 | 96 | 100 |
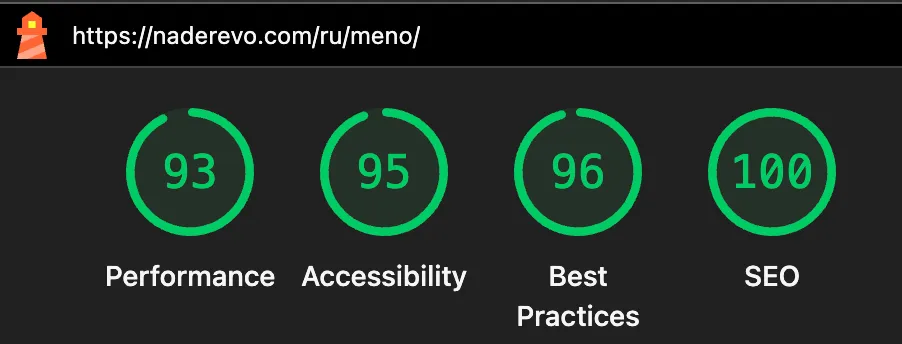
Лендинг MENO:
| Performance | Accessibility | Best Practices | SEO |
|---|---|---|---|
| 93 | 95 | 96 | 100 |
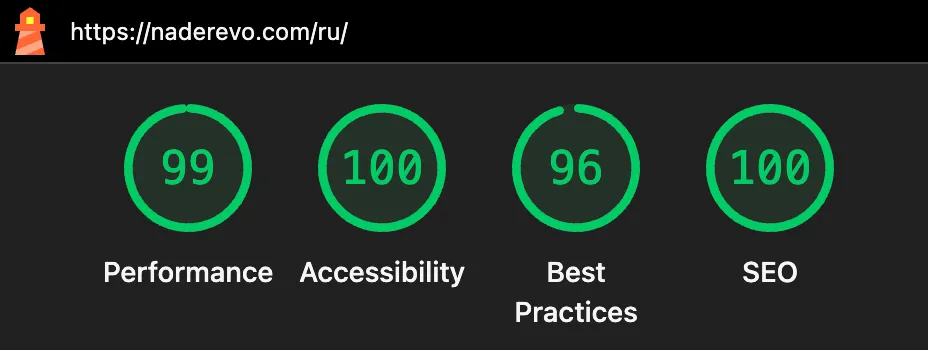
Главная - почти максимум по всем параметрам. Это заслуга Astro: статический HTML без клиентского JS грузится мгновенно.
Лендинг чуть ниже по Performance (93) и Accessibility (95) - там больше контента, скриншоты продукта, интерактивные секции. Это нормально. 93 - всё ещё зелёная зона, и я знаю, куда копать, если захочу дожать.
Зачем вообще прогонять Lighthouse: это бесплатная проверка на дурака. Пару минут - и вы видите, что забыли alt у картинки, что шрифт грузится блокирующим образом или что meta description пустой. Лучше узнать от Lighthouse, чем от пользователя, который ушёл с сайта через полсекунды.
Итого
Сайт запущен вчера. Трафика пока ноль. Но техническая база для того, чтобы поисковики и AI-модели увидели контент, - готова.
Что сделано:
- Статический сайт на Astro, два языка, чистый HTML
- SEO: canonical, hreflang, OG, structured data, sitemap, уникальные meta
- GEO: открытый robots.txt, author layer, Person schema, контент без клиентского JS
- POSSE: оригинал контента на своём сайте, синдикация на площадки
- Google Search Console и Яндекс.Вебмастер подключены
SEO и GEO - это марафоны. Но для GEO правила еще обновляются. Но если не начать сейчас - потом догонять будет сложнее.
Ссылки
Сайт: naderevo.com Бот MENO: @menoapp_bot